
検索エンジンに情報をインデックスされるためには検索エンジンロボット・ボット・スパイダーと呼ばれる巡回プログラムがサイト・ブログを訪れる必要があります。そこで、当ブログへ巡回してくるロボットの名称と特徴をまとめてみましたのでご参考下さい。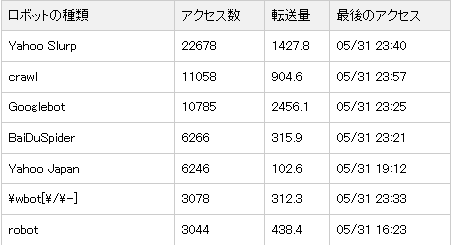
検索エンジンロボットの種類と巡回頻度
ここで実際に訪れてるクローラーがどんな役割を持ち、どういった狙いがあるのか?
ちょっとまとめてみようと思います(*´∀`)
Yahoo Slurp
ご存知世界のYahooの巡回クローラー・ロボットです。こちらは日本のYahooとは別ですが、日本のサイト・ブログも普通に巡回してきます。しかし、これは、アメリカでbingに移行が完了する2012年までという事で、いっぱい来てるからといって、安心できるものじゃないです
Googlebot
Googlebot とは、ご存知Google のウェブ クロール用ロボットです(「スパイダー」と呼ばれる場合もあります)。クロールは、Googlebot が Google のインデックスに追加する、新しいページや更新されたページを検出するプロセスです。クロールするサイト、クロールの頻度、各サイトから取得するページ数はコンピュータ プログラムによって決定されます。
BaiDuSpider
中国の検索サイト「百度」のために、ウェブサイトの情報を収集するロボット(クローラ)
噂ではリソースを食いつぶし、503エラーを多発させるという事もあるらしく、あんまりクロールされるのも嫌だなぁ・・という方は、意図的に拒否・ブロックするのも手です。ただ、グローバルな情報展開してる方は逆に売りこめていいかも?
Yahoo Japan
ご存知、日本のYahooの検索エンジンクローラーです
mediapartners-google
これは知ってお得なGoogleアドセンス関連のボットらしいです。Goolgeアドセンスを張った状態だと、マッチングが悪く英語の広告などが表示されますが、どうやらこちらのクローラーが来た後は、日本の広告が表示されるようになるようです。広告が英語の表示ばっかりなのは、もしかしたら、広告コードを張った後、Googleさんからクローラーが確認しにきてないのかもしれませんね。
⇒ アドセンスの知って得するmediapartners-google
feedfetcher-google
Feedfetcher はユーザーが追加したこのフィードを収集し、定期的に更新しますが、ブログ検索や Google のその他の検索サービスにはインデックスを登録しません(フィードは Googlebot でクロールされたときのみ検索結果に表示されます)。よくわからんw
Alexa (IA Archiver)
Alexa(アレクサ)とは、全世界のWEBサイトを調査し、訪問者数の多いページをランキングする事業を行っている企業。AlexaのWEBサイトでは、全世界全てのWEBページを訪問者数の多い順にランキング表示したものを確認する事が出来る。
Speedy Spider
スウェーデンの検索エンジンのようで、インデックスを構築するために使用される自動ウェブクローラ
AskJeeves
ASK検索エンジン用情報収集クローラー。以前は可能なかぎり早く検索できるようにインデックスの更新を1分ごとに行っていたけれど、最近はパタッとクローラーがこなくなったのは、ping送信でエラー多発してリストから外したからかもしれない。おそらくping送信先のリストとして大量に出回ってスパムサイトの登録が増加するのを対策してるのかもしれない
Nutch
Nutch は、商用ウェブ検索エンジンには無い透過性(公開性)をもたらすものです。 Nutch による検索結果は、充分に偏見が無いことがわかっており、安心して検索をまかせることができます。・・・って書いてたw
MSNBot
新しいBingのクローラー。2010年6月28日から、下記MSNBotは「bingbot」に変わっているそうです。bingのクローラーというけど・・当ブログにはなかなか訪れてくれてないようで・・何か方法があるのかな。同様に、msnbot\-mediaというクローラーもくるが、月に18回って・・もっとこいよwやる気ねーなマイクロソフト
mj12bot
こいつにはmj12botもどきのウイルスタイプと通常のクローラーの2タイプがいるらしく・・ちなみに本物は数ページクロールして去っていくそうですが、ウイルスだと急激にアクセス数が伸びるんだとか・・●:・∵;(ノД`)ノ ヒイィィィ ちなみに当ブログはわずか12って、少なw
yandex
yandexとはロシアの検索エンジンらしいです。という訳で早速突撃して検索してみたけど・・このブログから何がインデックスされているのだろう・・(-_-;)見つからない
Steeler
Steeler は 東京大学 喜連川研究室 で運用している Web クローラ (ロボット), すなわち自動的に Web 上のページを渡り歩くソフトウェア。Web 上に公開された文書を可能な範囲で収集し, 様々な社会現象の分析に活用することを目的としているようなので、害悪ではないです
magpie
magpieはbrandwatchという会社のクローラークローラーで通称「カササギ・クローラ」と呼ばれるもので、ソーシャルメディア情報から有用かつ関連する議論などを探し出し、ブログやニュースサイトなどユーザーの投稿を自動的に収集するロボットです。確かにソーシャルメディアなだけあって、転送量がめちゃくちゃ小さい。1217回のクロールで転送量はわずか「0.1」でしたw
cfnetwork
cfnetworkについて調べてみると、iosデバイスからのアクセスのようです。iOSのversionによって数字は違いますが、大元は一緒
facebookの情報収集用クローラー。アカウントでOGP設定などしている場合、訪れると思います
heritrix
HeritrixはJava言語で開発されているオープンソースソフトウェア。誰でも利用可能で、特定のドメイン、ドメイン配下のURLのみクロールなど柔軟な設定が可能なBOT。つまり、個人がカスタムしたクローラーとして巡回してるって事で、良いのか悪いのかを別として、ブロックしても問題ない対象です。実際微々たる回数のクロールで転送量も低い感じなのでほっといてもいいんですけどね
archive\.org_bot
中古ドメイン取得の際に、過去の運営履歴を確認するので同じみサイトWaybackMachineで利用するアーカイブの収集クローラー
phantom
phantomはスクレイピング(WEBサイトから情報を抽出する)クローラーで、取得した情報をHTMLファイルを書き出し、様々な用途で悪用カスタマイズできるようなので・・要ブロック対象ですね。コンテンツの主要な部分をパクられ、カスタム利用される恐れがあります
exabot
日本以外のどこからかのクロールボット。回数も少ないし害はない?
java\/[0-9]
javaから始まるクローラーかなり精度の低いプログラムで、短時間に何度も繰り返し訪れるなど、絨毯爆撃迷惑クローラー。ちなみに月に225回で転送量は6.6なので、絨毯ですらない(笑)
no_user_agent
海外サイトを翻訳すると2つの見方があるようです。手動robots.txtを無視するため、また、サイトを分析するなど、クロール者の目的を隠す、偽造するための悪質なボット。
もうひとつは、単にソフトウェア開発元で独自のユーザーエージェントを付けるのを忘れた等・・過去、FacebookがUA付け忘れがあった等を引用してるので有力。非常にブロックするか判断が迷う所ですが、場合によってはドメイン内のjsファイルなどを実行できるケースもあるという事でアクセスログなどでIPを確認し慎重な対処が必要です(※めんどくさい方は放置)
謎のクローラー・その他一覧
- crawl
- wbot
- favicon
- bot[\s_+:,\.\;\/\\-]
- [\s_+:,\.\;\/\\-]bot
- checker
- core
- robi
とまぁ、色んな所からクローラーってきてるみたいですね
一般的には検索エンジンクローラーやボットって来てくれるとインデックスされる!
と思いがちですが・・どうやら中には悪さするものもあるそうです((( ;゚Д゚)))ガクガク
悪質?不明なクロールロボットをブロックするには?
上記、自分でクロールの状況を調べて、こいつ・・悪質かどうかわからないけど、情報を拾われたくないな~という場合、個別に情報収集をブロックする方法としてrobot.txtを使う方法と、htaccessを使ってユーザーエージェント(アクセス元を指定)した上でブロックする2つの方法がありますが・・robot.txtで記述しても、無視するクローラーも中にはあるため、htaccessの利用がいいです
⇒ ユーザーエージェントでアクセス制限するhtaccess簡単作成
こちらに上記で調べたボット名を記述して「htaccessルール作成」を押すと簡単に作成できます










LEAVE A REPLY