
久しぶりに真面目にSEO(脱Google⇒duckduckgoからのアクセス)について考えたら見えてきた問題点。そうかGoogle依存はHTML5へのシフトから始まっていたんだ・・
理由:脱Google⇒duckduckgo利用者増加の流れ
世間一般、与えられた情報しか見てない人たちは、なぜそんな現象が起きているのかもわからないと思うが、そこは説明を省く(自分で理由を見つけよう。ただし、Googleでは見つからないけどなw)
今回はduckduckgo(ダックダックゴー)という利用者が急増している検索エンジンサービスから、検索して訪れるユーザーに対してコンテンツマッチさせるには、どうSEO対策をすればいいのか?これをまず検討してみて色々見えてきた事をまとめる
duckduckgoのSEOはGoogleと違う
duckduckgoはpingを受け付けていない(pingスパム対策)
duckduckgoはWEBマスターツールもない(サイトオーナーの監視もない)
pingを飛ばせない(直接)受け取ってもらえないとなるとRSS(更新データ)が届かない。ならば、サーチコンソールのようにサイトマップ(サイト構造の地図)だけでも登録できないものだろうか?と調べてみたが・・それもできない・・さて困った(-ω-;)ウーン
duckduckgoはbingから情報を拾っているらしい
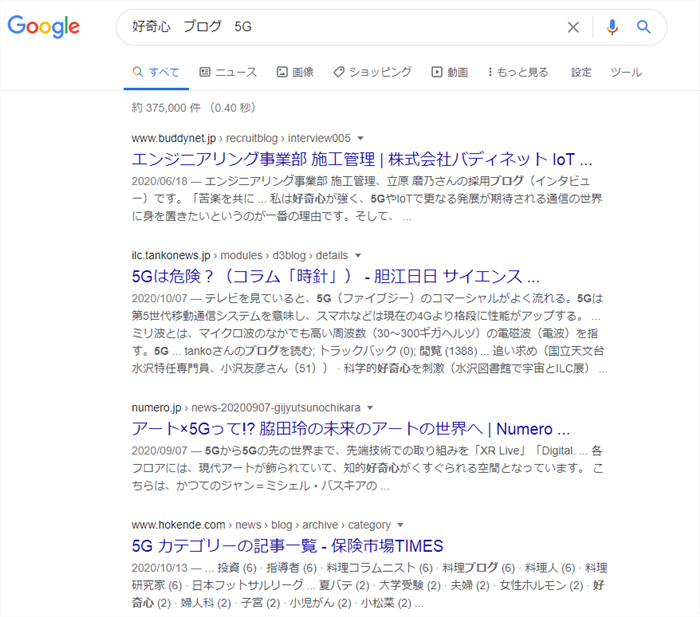
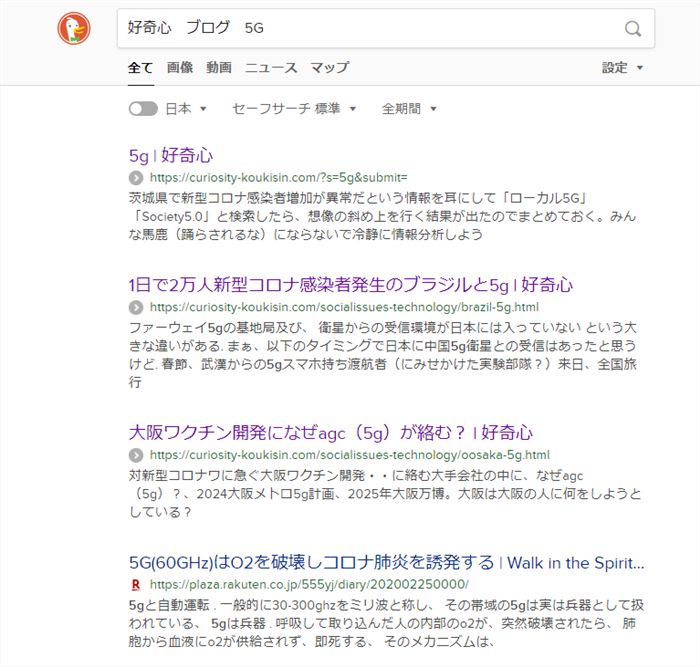
duckduckgoの検索結果は、明らかにGoogleとは違う。その例を同じ検索ワードでチェック
例:google
例:duckduckgo
例:bing
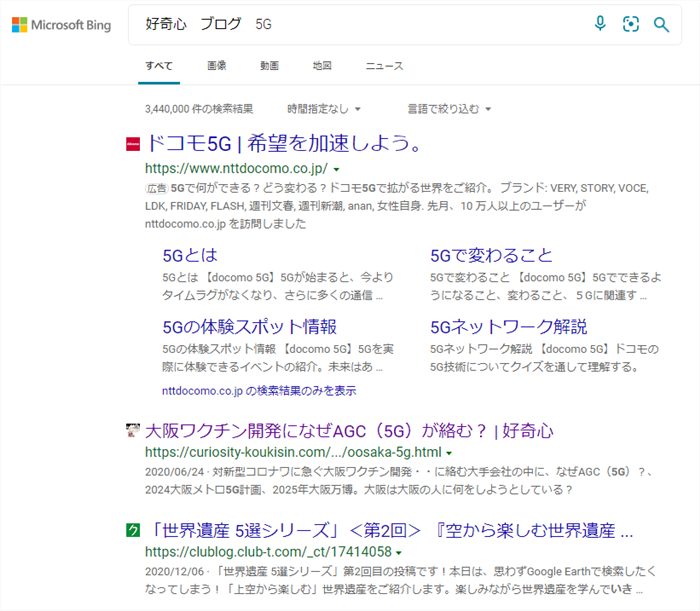
検索キーワードというのは、検索者の知りたい言葉が詰まったニーズです。「好奇心 ブログ 5G」 ここまで絞り込む人が検索する目的って誰がどう考えてもわかりますよね
①ブログ名を知ってる⇒②ブログと媒体を絞り込んでる⇒③ブログの中の特定の内容を探してるという、仮に、自分で書いた自分のブログの記事の内容を参照しようとして検索した場合のキーワードとして考えても、明らかにGoogleの検索結果がユーザーのニーズに答えた検索結果ではないのが目に見えてわかりますよね
そんなキーワードで探す奴はいねぇ=検索条件の絞り込みをしてて出てこないのは、明らかに検索結果に掲載する情報を選んでいるという訳です

ちなみに次のページ・・次のページくらいには一個くらいは・・って思うでしょ?
10ページくらい見ていっても「1つもない」からおかしいんです(笑)
ちなみにduckduckgoはこのbingの検索結果およびクロールした情報を拾い集め、逆に言えば、Googleの情報をほとんど入れないとの事(だから検索結果が違う)
WEBサービスとしては独自路線でおもしろい戦略と差別化、なんでもかんでもSNS発信で高速で膨大に情報が生まれる時代だからこそのニッチな需要
だから今、Googleでは探したい情報が見つからない代わりに、見たくもない偏向報道のプロパガンダを見せられる事に嫌気がさした人たちが、duckduckgo、あるいは bing といった違う媒体へと移り始めているんです
これはもう予想してた未来としか言いようがない(多くの人が離れた理由はアメリカ大統領選挙だけど)
それにあわせて情報を発信する側もまた、その情報を知りたいニーズに合わせて、新しい環境に適用していく必要があるんですがね・・いや~盲点でした(;´∀`)前にも気にした事はあったんだけど・・まさか今再び問題になるとは・・って訳で今日の本題はここ!
bingはHTML5を重要視していない問題
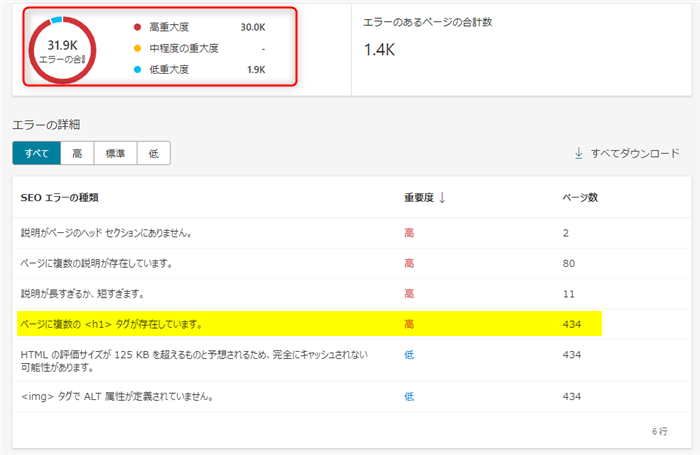
duckduckgoがbingから情報を得ているのであれば、bingのWEBマスターツールにサイトを登録してpingで更新を伝え、bingのクローラーに情報を拾ってもらえばいいじゃないか!と期待した結果がこれだ・・
以前もHTML5がスタンダードになりかけの時に、bingにするか?Googleの新基準に合わせるか?で悩んだ記事を書いた事がある(※削除したっぽい)
その当時は、いずれbingも時代の流れでHTML5のSEOに準拠して対応していくだろうと考えていたが・・今もbingはHTML構文の観点からH1はページに複数あるべきではない!という主張(クローラーの認識)をしているようだ
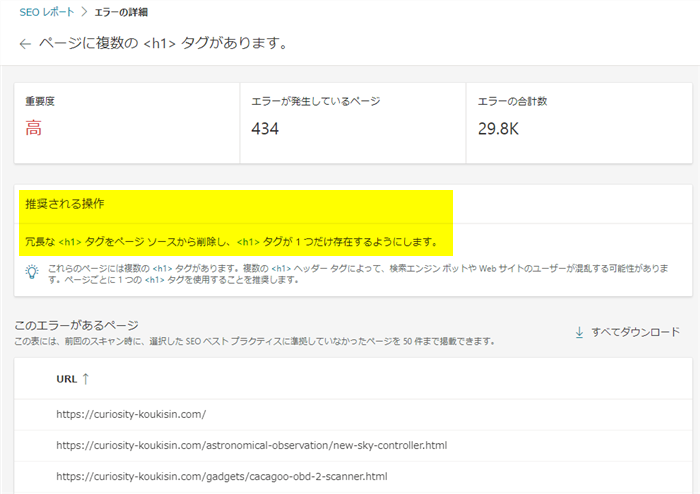
これがHTML5の構文ルールに準拠してきた人たちにとって致命的なポイントとも言える修正不可能な用途。2014年の段階で私はこれを問題視してたようだ(過去記事から)
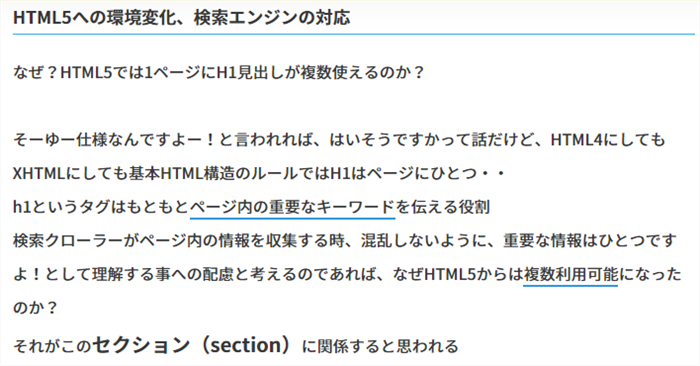
現在はワードプレスのデフォルトテンプレートでも、SEO対策済みのテンプレートでも、HTML5準拠の構造ではH1タグはページに複数あっても問題ないという考え方の元、自動的に記事一覧のタイトル見出しはセクションで複数H1記述になるようになっている
しかし、旧来のXHTMLやHTML4.01の時代の構文ではH1という重要な見出しはページにひとつのみ!というルールがある。これは情報を集めるクローラー(ロボット)にとってそのページは何について重要としてるのか?というシンプルな目安でもある
現時点で、bingのWEBマスターツール上でこれがエラー項目としてカウントされるのであれば、GoogleのSEOに特化したブログ(H1複数利用)は対応が難しい
またHTML5対応ブラウザで高速読込を行うようにgz圧縮やCSS・スクリプトの最適化ファイルなどについても、bingのクローラーは???(;´∀`)というエラー反応を示している
ぺージ数に対してインデックスされてる数の少なさを考えるとGoogleに最適化されたサイトマップの自動生成では取りこぼしが多いようなので、サイトマップを登録してもあまり効果はなさそうだ
今まで通りGoogleにあわせるのか?
それともbing・・の背後に増えつつあるduckduckgoユーザーに焦点をあわせるか?
普通なら圧倒的に分母の多さからGoogle一択 というのが今までの話
でも世界の表裏が見えてる人は、今とてもGoogleへの信頼が揺らいでると思う
Googleでしか使えないampへの完全シフトの場合はbingのクローラーは情報を把握できないだろうし、そうなるとduckduckgoも拾わない
沈みゆくビッグテックと共にいく?再び選択の時か・・それとも国家反逆罪へ加担した組織の腐った部分だけ取り除かれて良いサービスが再び戻ってくるのか
いずれにせよ、現時点じゃどれだけGoogle準拠のSEOを行った所で検索からアクセスが来る事はほとんどないから考える必要がある(ブログの多くが検索結果に出ないのが事実)
まとめ:duckduckgoが求められた理由の深さを考えよう
昔からGoogle、yahooとか検索エンジンというのは便利さで求められた
それがduckduckgoという不便な検索エンジンにニーズが高まっている理由は
伝えられる情報への信頼度の問題
見たい、知りたい、確認したい情報を見れない問題
片方に存在してるのに片方にでてこない情報の隠蔽・検閲の問題
人が情報を探すのは、達成したいシンプルな目的があるから、そのヒントやアドバイスに関連する情報を求めている
膨大な情報を管理しているにも関わらず、必要な情報がでてこない、意図的に検閲している大手検索エンジンには愛想がつきた
人は便利さよりも、真実と信頼を取った それだけの事
本当に自分が興味がある事、知りたい事をさっと検索して、その道を先に進んでる人の情報や、それに役立つ道具を提供している企業の情報が見つかる
これが 理想的な検索エンジンの姿 そういう場になればいいな(。-人-。)祈
ちなみにbingでインデックスされてる私の記事は、ちゃんとオリジナル情報を発信をしているブログ運営者の記事ページからの引用形式で紹介されているナチュラルリンク(バックリンク)がついてました
そしてそれをduckduckgoでも拾ってる事を考えれば、被リンクSEOが有効なのかもしれないね
ただし、ツイッターやフェイスブックでいいね!が大量についてる記事とか関係なかったので、SNSのリンクは無視してるみたい(笑)








LEAVE A REPLY